Problem 
We arrive at a webpage that says:
There is nothing on this page
Solution 
This is more of a “theory” kind of challenge, we got a hint when we inspect the page.

We have to know how google does it’s job of indexing webs, through web crawling. Now what if a website doesn’t want a certain part of it’s web to be indexed by web crawlers? We use a standard that is the robots.txt file located in the “root” folder of the web, this file acts as a “rule” for the web crawlers (ones who follow rules). So let’s see what’s in it.

We see that all web crawlers (User-agent: *) aren’t allowed to crawl into the s3cr3t/ folder, so let’s see what’s in it anyway.
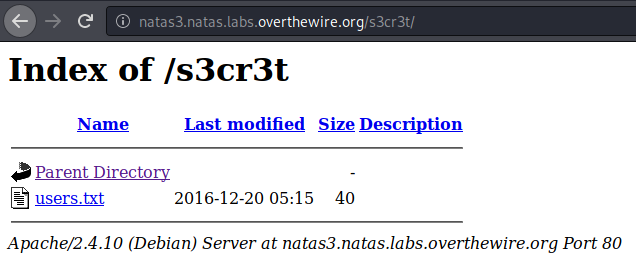
We see there’s a file, in it is our flag.

Flag 
Z9tkRkWmpt9Qr7XrR5jWRkgOU901swEZ
Takeaway 
- Always check the
/robots.txtfile in a web ctf
| ‹ Previous in Web exploitation: Natas2 | Next in Web exploitation: Natas4 › |